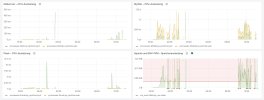
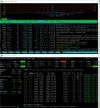
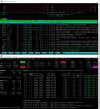
There is a Fail2ban jail called plesk-apache-badbot, but it uses an outdated list of bots.
I never use it because I had severe server issues (it blocked the wrong IP addresses) caused by that jail.
I created a more up-to-date list of frequently used bots in the post above. I suggest you start with that before activating the fail2ban jail.
I never use it because I had severe server issues (it blocked the wrong IP addresses) caused by that jail.
I created a more up-to-date list of frequently used bots in the post above. I suggest you start with that before activating the fail2ban jail.