We have a large file that we sometimes need customers to download from our server. We send them a link, and most download it fine. But sometimes they get a 404 error. We asked a customer for a screenshot today, and they took a photo instead so part of it is cropped out, but the link is correct, the browser appears to be Chrome (not sure because it's cut off in the photo) and it's showing the website's 404 page (not a generic browser error.)
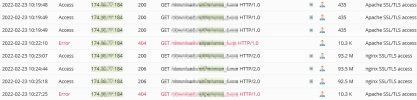
I found it in the logs, and I can't make heads or tails out of this, but I think it has something to do with the server's response to the HTTP REQUEST. This is most of the attempts the customer made this morning - there are 3 HTTP/2.0 requests that appeared to have been somewhat successful (except that the file is actually over 200mb) so there may be other issues on the customer's end.
I've tested from multiple browsers on multiple computers and can always download the file successfully. Looking through the last few weeks of logs, I can see that the 404s on this file are ALWAYS an HTTP/1.0 request, and are often followed up by a successful download with an HTTP/2.0 request but not always.
My concern is that the server somehow isn't communicating clearly with some browsers (or at certain times?) regarding the HTTP protocols. I also realize it could be an ancient browser, but I think that's highly unlikely, and definitely not the case this morning.
Any ideas?
I found it in the logs, and I can't make heads or tails out of this, but I think it has something to do with the server's response to the HTTP REQUEST. This is most of the attempts the customer made this morning - there are 3 HTTP/2.0 requests that appeared to have been somewhat successful (except that the file is actually over 200mb) so there may be other issues on the customer's end.
I've tested from multiple browsers on multiple computers and can always download the file successfully. Looking through the last few weeks of logs, I can see that the 404s on this file are ALWAYS an HTTP/1.0 request, and are often followed up by a successful download with an HTTP/2.0 request but not always.
My concern is that the server somehow isn't communicating clearly with some browsers (or at certain times?) regarding the HTTP protocols. I also realize it could be an ancient browser, but I think that's highly unlikely, and definitely not the case this morning.
Any ideas?