Hello,
I would like to request your help regarding memory usage, could not find any relevant things about what i encounter.
I recently did some performance tuning on MySQL in order to lower its memory usage
Server specifications :
OS : Debian 9.13
Plesk version : Plesk Obsidian Version 18.0.30 Update #3
RAM : 16 Go
CPU : 8
Disk : 512 Go ( HDD )
FS : XFS
Here is the list of what i tuned :
General stuff
InnoDB specific
After i pushed these values and restarted MySQL i was really happy because i could see a huge memory usage improvement (event after a few hours MySQL has restarted)
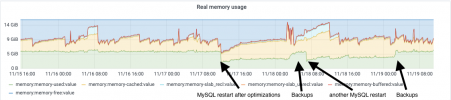
But, i noticed that the daily backups that occurs during the night ( 2:30 in my case ) are reclaiming a lot of memory which is completely normal, unfortunately even after the backups are done i can see on the grafs that the memory is not released, it just keep at the same level as it was during the backups (i mean the memory_used metric).
Is it normal ? Shouldn't the system reclaim that memory once backups are done ? I mean it's not in the cached part as some posts suggest.
I attached a screenshot from the Real memory usage graf with details, we can see that after the last backup the memory usage keep high.
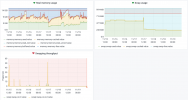
( Hopefully, those MySQL optimizations have permitted to lower the swap usage (second screenshot) but still i was expecting to gain on memory_used )
Thank you in advance for your advices / help
Cheers
I would like to request your help regarding memory usage, could not find any relevant things about what i encounter.
I recently did some performance tuning on MySQL in order to lower its memory usage
Server specifications :
OS : Debian 9.13
Plesk version : Plesk Obsidian Version 18.0.30 Update #3
RAM : 16 Go
CPU : 8
Disk : 512 Go ( HDD )
FS : XFS
Here is the list of what i tuned :
General stuff
INI:
[mysqld]
max_connections = 100
key_buffer_size = 1G
query_cache_size = 64M
table_cache = 16384
max_heap_table_size = 128M
tmp_table_size = 128M
open_files_limit = 32768InnoDB specific
INI:
[mysqld]
innodb_io_capacity = 2000
innodb_read_io_threads = 64
innodb_write_io_threads = 64
innodb_thread_concurrency = 0
innodb_buffer_pool_size = 4GB
innodb_log_file_size = 1GBAfter i pushed these values and restarted MySQL i was really happy because i could see a huge memory usage improvement (event after a few hours MySQL has restarted)
But, i noticed that the daily backups that occurs during the night ( 2:30 in my case ) are reclaiming a lot of memory which is completely normal, unfortunately even after the backups are done i can see on the grafs that the memory is not released, it just keep at the same level as it was during the backups (i mean the memory_used metric).
Is it normal ? Shouldn't the system reclaim that memory once backups are done ? I mean it's not in the cached part as some posts suggest.
I attached a screenshot from the Real memory usage graf with details, we can see that after the last backup the memory usage keep high.
( Hopefully, those MySQL optimizations have permitted to lower the swap usage (second screenshot) but still i was expecting to gain on memory_used )
Thank you in advance for your advices / help
Cheers