watchturks
New Pleskian
- Server operating system version
- AlmaLinux 8
- Plesk version and microupdate number
- 18.0.57
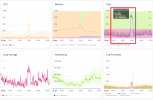
Hello, I have a weird problem. My server's disk usage increases by 75%-100% at the same time every day. Meanwhile, freezing and slow loading problems occur on the server. Since I broadcast videos via the server, loading and buffering problems occur due to this problem.
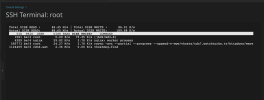
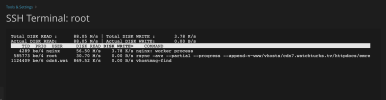
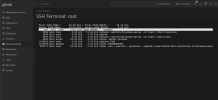
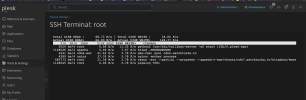
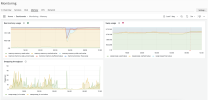
There is no cron or backup set for this time. I've added the image below showing disk usage. This happens at the same time every day.
CleanShot 2024-01-05 at 10.32.07 - Photo 1
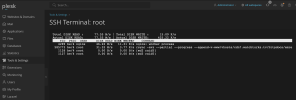
CleanShot 2024-01-05 at 10.33.06 - Photo 2
We suspected that raid check might occur at this time and we disabled it. However, the problem still persists.
I found some topics similar. It was mentioning that plesk maintenances may occur it. Is there anyone help me out?
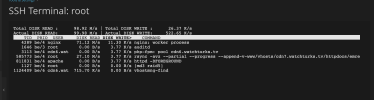
There is no cron or backup set for this time. I've added the image below showing disk usage. This happens at the same time every day.
CleanShot 2024-01-05 at 10.32.07 - Photo 1
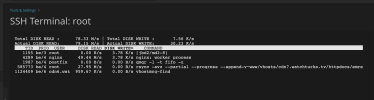
CleanShot 2024-01-05 at 10.33.06 - Photo 2
We suspected that raid check might occur at this time and we disabled it. However, the problem still persists.
I found some topics similar. It was mentioning that plesk maintenances may occur it. Is there anyone help me out?