Zalem Citizen
New Pleskian
Hello,
My Plesk is hosting about 140 websites. Some very small and with few visitors, some larger, with lots of static content, all on cms like wordpress and a few drupal, and cron tasks.
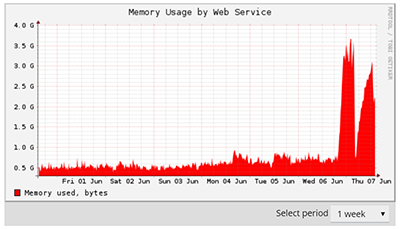
Site visits increase each year on summer so we are entering a heavy duty period.
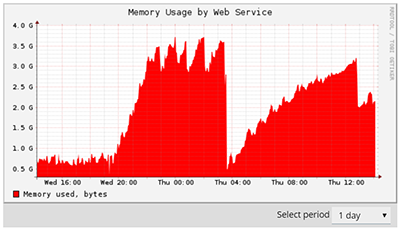
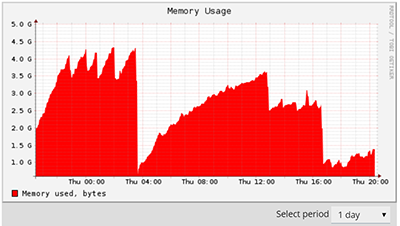
For a few days, server randomly fails : apache cpu usage increases dramatically and the server answers with 504 time out. No memory outage, disks I/O seems ok.
Server is an Ubuntu 16.04 running multiple version of PHP (mainly 5.6 and 7.1) through FPM. MySQL is running locally.
Last time was reported by my uptime monitors yesterday at 20:55.
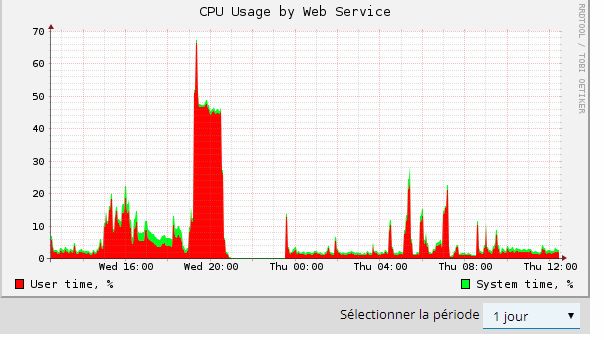
Health monitor is showing a peak in Apache CPU round 19:15-25, then a lot of sleeping processes.
Syslog shows this :
Apache log shows this, just before all websites went down :
So I checked apache modules and saw mpm_prefork is running.
Shouldn't it be running mpm_event instead to multithread and forward requests efficiently to PHP-FPM through FastCGI ?
Could it be the origin of my problem ?
Thanks !
My Plesk is hosting about 140 websites. Some very small and with few visitors, some larger, with lots of static content, all on cms like wordpress and a few drupal, and cron tasks.
Site visits increase each year on summer so we are entering a heavy duty period.
For a few days, server randomly fails : apache cpu usage increases dramatically and the server answers with 504 time out. No memory outage, disks I/O seems ok.
Server is an Ubuntu 16.04 running multiple version of PHP (mainly 5.6 and 7.1) through FPM. MySQL is running locally.
Last time was reported by my uptime monitors yesterday at 20:55.
Health monitor is showing a peak in Apache CPU round 19:15-25, then a lot of sleeping processes.
Syslog shows this :
But I can't figure if it could be related or not.Jun 6 19:24:19 <hostname> systemd[1]: Stopping User Manager for UID 10006...
Jun 6 19:24:19 <hostname> systemd[19718]: Stopped target Default.
Jun 6 19:24:19 <hostname> systemd[19718]: Stopped target Basic System.
Jun 6 19:24:19 <hostname> systemd[19718]: Stopped target Paths.
Jun 6 19:24:19 <hostname> systemd[19718]: Stopped target Sockets.
Jun 6 19:24:19 <hostname> systemd[19718]: Stopped target Timers.
Jun 6 19:24:19 <hostname> systemd[19718]: Reached target Shutdown.
Jun 6 19:24:19 <hostname> systemd[19718]: Starting Exit the Session...
Jun 6 19:24:19 <hostname>systemd[19718]: Received SIGRTMIN+24 from PID 21716 (kill).
Jun 6 19:24:19 <hostname> systemd[1]: Stopped User Manager for UID 10006.
Apache log shows this, just before all websites went down :
[Wed Jun 06 20:51:43.107882 2018] [mpm_prefork:error] [pid 29055] AH00161: server reached MaxRequestWorkers setting, consider raising the MaxRequestWorkers setting
So I checked apache modules and saw mpm_prefork is running.
Shouldn't it be running mpm_event instead to multithread and forward requests efficiently to PHP-FPM through FastCGI ?
Could it be the origin of my problem ?
Thanks !