- Server operating system version
- Ubuntu 20.04.5 LTS
- Plesk version and microupdate number
- Plesk Obsidian Version 18.0.46 Update #2
Hello,
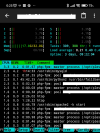
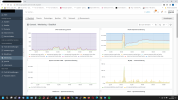
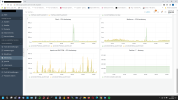
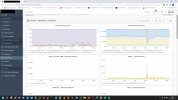
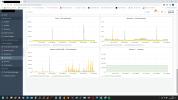
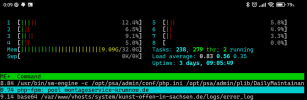
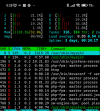
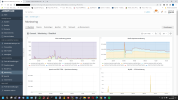
on my Plesk server, around 0:05, the RAM consumption shoots up immeasurably. After about 30 minutes it's ok again.
What is Plesk doing at this time and how can I fix it? It was so bad that no websites could be accessed.
I had set the cron jobs, which were set to 0:00 in the Plesk administration, to a different time because it was the day before yesterday.
Backup is made at 3:00 am
on my Plesk server, around 0:05, the RAM consumption shoots up immeasurably. After about 30 minutes it's ok again.
What is Plesk doing at this time and how can I fix it? It was so bad that no websites could be accessed.
I had set the cron jobs, which were set to 0:00 in the Plesk administration, to a different time because it was the day before yesterday.
Backup is made at 3:00 am