Hi,
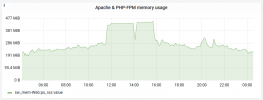
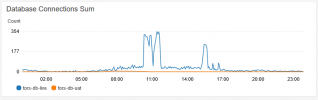
I'm struggling to narrow down some really high spikes in apache and php-fpm memory usage, which coinsides with a complete drop in apache and php-fpm cpu usage. See attached images.
This is causing a gateway timeout message on the website during these memory spikes.
I've gone through the syslog but nothing stands out as the culprit? Can anyone suggest where to look or has had similar issues.
Note: This doesn't appear to happen at regular times. It happened yesterday when traffic was relatively low (bank holiday monday)
I'm struggling to narrow down some really high spikes in apache and php-fpm memory usage, which coinsides with a complete drop in apache and php-fpm cpu usage. See attached images.
This is causing a gateway timeout message on the website during these memory spikes.
I've gone through the syslog but nothing stands out as the culprit? Can anyone suggest where to look or has had similar issues.
Note: This doesn't appear to happen at regular times. It happened yesterday when traffic was relatively low (bank holiday monday)


")