- Server operating system version
- AlmaLinux 8.9 (Midnight Oncilla)
- Plesk version and microupdate number
- 18.0.59 Update #2
Goodmorning,
We have a plesk server running with some domains on it. Every 1-2 days plesk randomly freezes and wont come back untill i reboot de VPS itself.
Monitoring shows constant 2-10% cpu and 30% memory usage, no strange behavior in that.
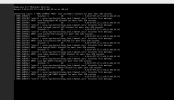
This morning we hade the same issue and on the VPS console i saw the errors, i've attached them in this post.
Could this be connected with the freeze issue? Any idea what else it could be that is causing this(maybe its a known bug)?
We have this VPS for 4 months now and the issues started about 1 month ago and the interval between the freezes are increasing.
Thanks in advance.
We have a plesk server running with some domains on it. Every 1-2 days plesk randomly freezes and wont come back untill i reboot de VPS itself.
Monitoring shows constant 2-10% cpu and 30% memory usage, no strange behavior in that.
This morning we hade the same issue and on the VPS console i saw the errors, i've attached them in this post.
Could this be connected with the freeze issue? Any idea what else it could be that is causing this(maybe its a known bug)?
We have this VPS for 4 months now and the issues started about 1 month ago and the interval between the freezes are increasing.
Thanks in advance.