Hi, I don't know if this is a legit request for the forum because probably there is no Plesk issue here, but I don't know what to do anymore, so last chance.. 
I have set up two identical websites using Wordpress+Woocommerce (one the "public" shop, the other one is for "resellers"), every now and then the CPU spikes @ 100% and the entire VPS hangs; slooow connection through ssh and a reboot is the only way to get back the server functionalities.
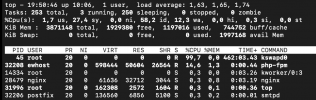
I recently managed to "see" this in action with top shell command open and it seems that the PHP-FPM process just goes off the roof when using the WP admin panel, sometimes this just causes a general slowing down, eventually hangs the entire VPS.
I tried changing the PHP version (now I am 7.2), checking plugins and upgrading the VPS CPU cores (now 4); it still causes the issue every now and then.
I am asking if someone has some insight about what to check, or eventually if I can just limit the CPU for that specific domain so at least the VPS and the other services stay on.
Thanks for every bit of help!
I have set up two identical websites using Wordpress+Woocommerce (one the "public" shop, the other one is for "resellers"), every now and then the CPU spikes @ 100% and the entire VPS hangs; slooow connection through ssh and a reboot is the only way to get back the server functionalities.
I recently managed to "see" this in action with top shell command open and it seems that the PHP-FPM process just goes off the roof when using the WP admin panel, sometimes this just causes a general slowing down, eventually hangs the entire VPS.
I tried changing the PHP version (now I am 7.2), checking plugins and upgrading the VPS CPU cores (now 4); it still causes the issue every now and then.
I am asking if someone has some insight about what to check, or eventually if I can just limit the CPU for that specific domain so at least the VPS and the other services stay on.
Thanks for every bit of help!