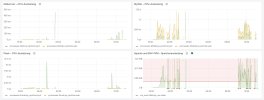
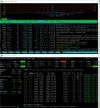
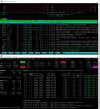
Maybe relevant or maybe not. These are some things I've done in the past to address similar issues with servers that run lots of WP sites and user CPU starts to creep.
- Reduce pm.max.children in PHP settings (did it at the service plan level). I've lowered this to 4 without causing any detectable impact on websites.
- Use FPM application served by NGINX
- In the panel.ini, there are some directives you can use to stop Plesk itself from continuously crawling your sites to generate thumb nail images to display for each domain in Plesk (this was a huge reduction in CPU for me as this process was spawning PHP-FPM's like crazy for WordPress sites)
- Use fail2ban to check for login probes against WordPress. I block an IP after 1 bad login for 5 minutes, and then if same occurs for that IP repeatedly, over short period, drop the hammer on it and block it for a long time (this catches a ton of bad actors)
- Make sure fail2ban is rolling up blocks...so that any IP caught with multiple actions is getting blocked for long periods
- In WP Toolkit, for every WP site, make sure to enable every security setting in the security check
- If memory buffer cache is always super high, implement a cron to clear it hourly.
- Implement Web Application Firewall (modsecurity). I set it to the thorough setting.
I'm sure there have been other small items, but in totality, the above seems to bring CPU down a lot and keep servers in check. No customer complaints either about WP performance.